알고리즘
추상적이고 이상적인 절차를 기술한 것
구현에 필요한 세부 사항과 현실적인 고려 사항을 무시
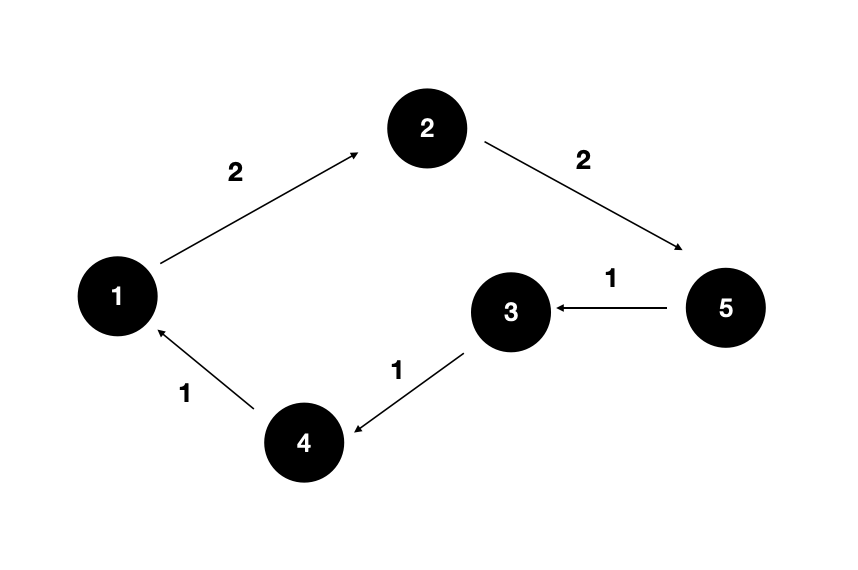
알고리즘은 추상적이고 이상적인 절차를 기술한 것으로, 구현에 필요한 세부사항과 현실적인 고려사항을 무시한다. 알고리즘은 정확하고 명로한 레시피이다.
알고리즘은 결국 멈춰야 함
프로그램
실제 컴퓨터가 과제를 완료하기 위해 수행해야 하는 모든 단계를 구체적으로 서술
하나 이상의 알고리즘이 컴퓨터가 직접 처리할 수 있는 형태로 표현된 것
실직적인 문제도 신경 써야 함(메모리 부족, 제한된 프로세서 속도, 유효하지 않거나 악의적으로 잘못된 입력 데이터, 하드웨어 결함, 네트워크 연결 불량, 인간적인 약점)
실제 컴퓨터가 과제를 완료하기 위해 수행해야 하는 모든 단계를 구체적으로 서술한다. 불충분한 메모리, 제한된 프로세서 속도, 유효하지 않거나 악의적으로 잘못된 입력 데이터, 하드웨어 결함, 네트워크 연결 불량, 인간적인 약점 등의 문제가 포함된다.
알고리즘과 프로그램 사이에는 명확한 차이점이 있다.
알고리즘이란 문제를 해결하기 위한 일련의 정해진 절차를 의미한다. 개념적이고 추상적인 형태로 표현되며, 어떤 언어로도 표현될 수 있다. 알고리즘은 문제를 해결하는 방법을 구체적으로 정의하며, 주어진 입력에 대해 예상 가능한 출력을 제공해야 한다.
프로그램은 이 알고리즘을 특정 프로그래밍 언어로 구현한 것이다. 컴퓨터에 의해 실행될 수 있는 구체적인 코드입니다. 프로그램은 알고리즘을 실제로 동작하게 하는 방법에 초점을 맞추며, 이 과정에서 여러 현실적인 제약 사항을 고려해야 한다. 메모리 용량, 프로세서 속도, 입출력 데이터의 유효성, 하드웨어의 기능, 네트워크 상태 등이 포함된다.
따라서 알고리즘과 프로그램을 비교하면, 알고리즘은 이상적인 요리 레시피라고 볼 수 있다. 이 레시피는 어떤 요리사에게도 전달될 수 있으며, 재료와 조리 방법을 제공합니다. 반면, 프로그램은 이 레시피를 구체적으로 실행하는 요리사라고 할 수 있다. 요리사는 주방의 환경, 재료의 상태, 조리 도구 등의 실제 사항을 고려해야 한다.
'CS > 1일 1로그 100일 완성 IT 지식' 카테고리의 다른 글
| 26로그 - 고수준 언어에서 프로그램 실행까지 (0) | 2023.06.29 |
|---|---|
| 25로그 - 다른 프로그램을 처리하기 위한 프로그램 (0) | 2023.06.29 |
| 22로그 - 10개 도시를 최단거리로 여행하는 법 (0) | 2023.06.15 |
| 21로그 - 검색을 쉽게 만드는 정렬 : 선택 정렬 vs 퀵 정렬 (0) | 2023.06.15 |
| 20로그 - 10억 개 전화번호에서 이름 찾기 : 이진 검색 (0) | 2023.06.15 |